Audit, evals, deployment: the operating loop behind applied AI deployments
Most AI projects fail in the gap between demo performance and production reality. The fix is an operating loop: audit the workflow, build evals that match real pressure, deploy with reliability, then iterate based on failures.
Why pilots get stuck
Two things are usually true at the same time:
- The model is “good enough” in a clean demo.
- The system fails in the messy branches: missing context, tool errors, ambiguous instructions, weird data, latency spikes, and humans doing unpredictable things.
Applied AI only becomes durable when you treat it like a production system, not a prompt.
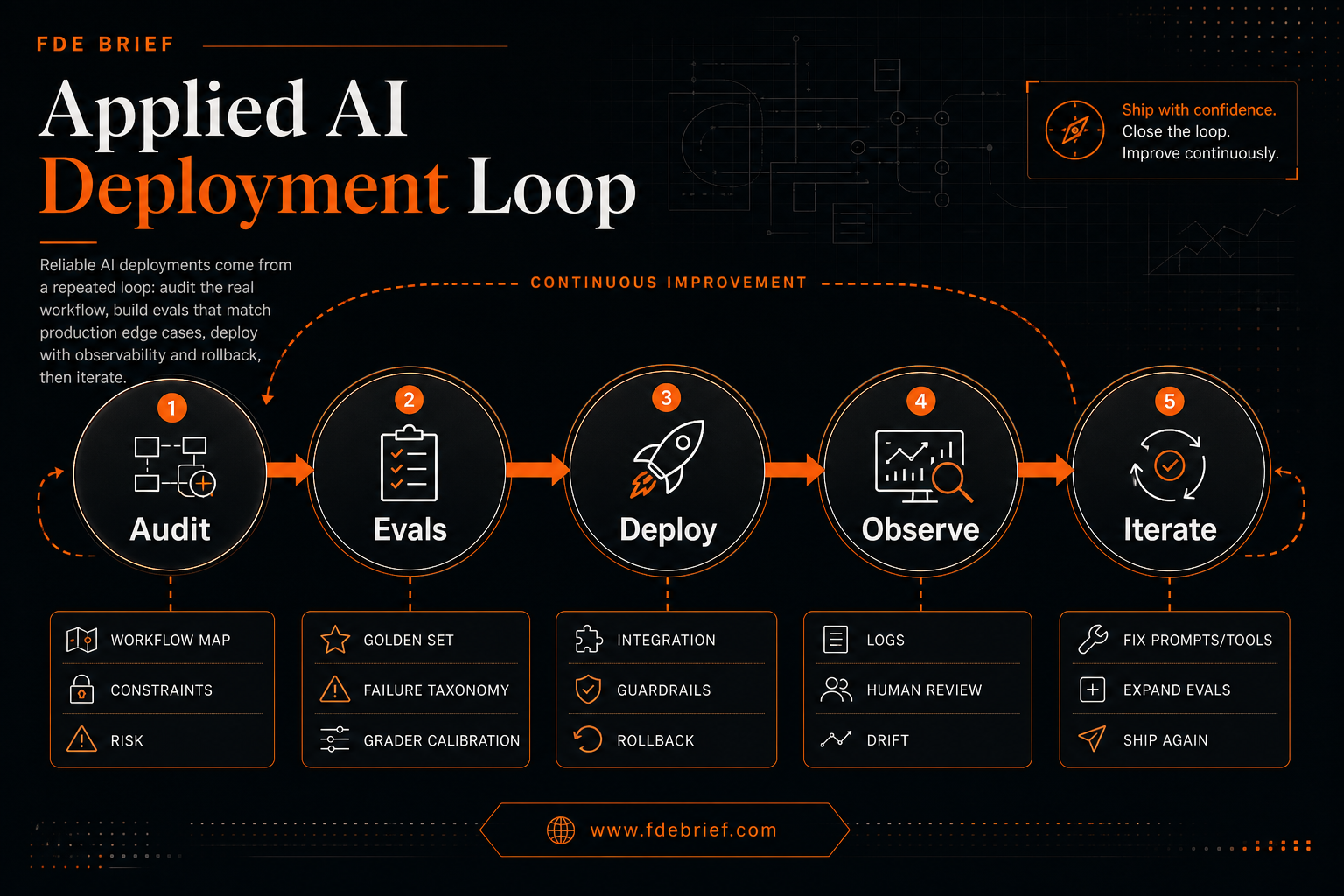
The loop: audit → evals → deploy → observe → iterate
This is the practical loop many FDE-style teams end up running, even if they do not call it this.
Operating contract: every deployment cycle produces (1) an audit artifact, (2) an eval set that reflects production reality, and (3) a deployment plan that includes observability and rollback.
1) Audit the workflow (not the model)
Start by auditing the actual workflow and environment. “Build an agent” is not a workflow.
- Workflow map: what inputs exist, who owns them, what outputs matter, and where humans must approve.
- Constraints: latency, privacy, offline modes, audit logs, and compliance requirements.
- Failure cost: what happens when the system is wrong — and how you detect it quickly.
The audit step turns vague requirements into testable responsibilities.
2) Build evals that match production pressure
Evals are how you make quality measurable. Without evals, the team debates feelings.
- Golden set: real examples that capture the hard edge cases, not just typical cases.
- Failure taxonomy: a small set of named failure types you can count (missing tool call, wrong action, hallucinated data, unsafe output, etc.).
- Calibration: if you use LLM-based graders, periodically verify them against human judgment.
Good evals become the shared language between product, engineering, and whoever owns risk.
3) Deploy like a reliability engineer
Shipping “the prompt” is not deployment. Deployment means it works with real data, real users, and real tool failures.
- Integration: auth, permissions, data contracts, tool retries, and timeouts.
- Guardrails: constraint checks, allowed-action boundaries, and safe fallbacks.
- Rollback: a fast way to turn it off or degrade gracefully when the system regresses.
4) Observe what breaks, then iterate
Observation is where demos become systems.
- Logs you can read: capture tool calls, errors, and the “why” behind decisions when possible.
- Human review lanes: route uncertain cases to a human instead of guessing.
- Drift watch: track changes in data and user behavior that change success criteria.
Iteration means: add failing cases to evals, improve prompts/tools, and ship again.
How this shows up in FDE interviews
If you want to hire for applied AI deployment skill, interview for the loop:
- Ask for an example where a demo failed in production and how the candidate diagnosed it.
- Ask how they would build an eval set for a workflow that has multiple correct answers.
- Ask how they would design a safe fallback for a tool call that sometimes fails.
For the full interview breakdown, use Forward Deployed Engineer Interview Guide. If you want candidate proof-of-work, use FDE Portfolio Projects That Actually Signal The Role.
Sources
- OpenAI: How evals drive the next chapter in AI for businesses
- OpenAI API: Evaluation best practices
- Anthropic: Demystifying evals for AI agents
- The Pragmatic Engineer: The Pulse — Forward deployed engineering heats up again
- Vas M: Forward Deployed Engineering 101 (thread)
The question
What is the first failure mode you expect when you ship your “AI pilot” into production — and what eval would catch it before the customer does?
Get the next FDE role brief
Role teardowns, career maps, and field notes for engineers who live at the customer.